Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Инструкция;
- Синтаксис;
- Директивы;
- Проверка работы;
Директивы и инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
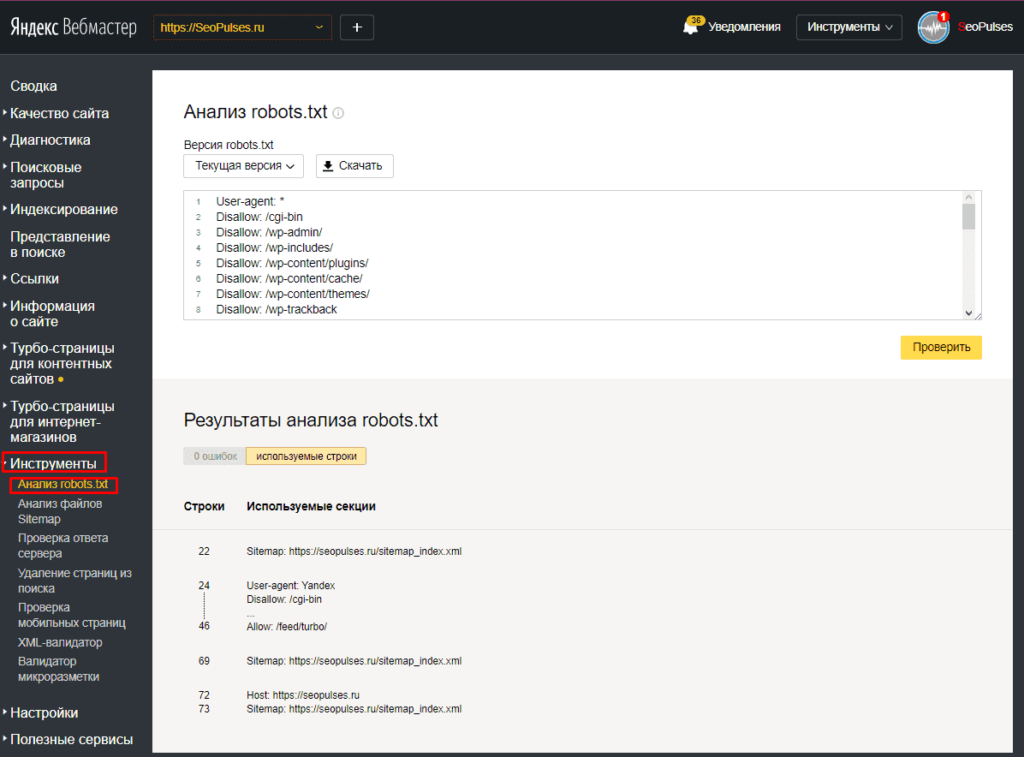

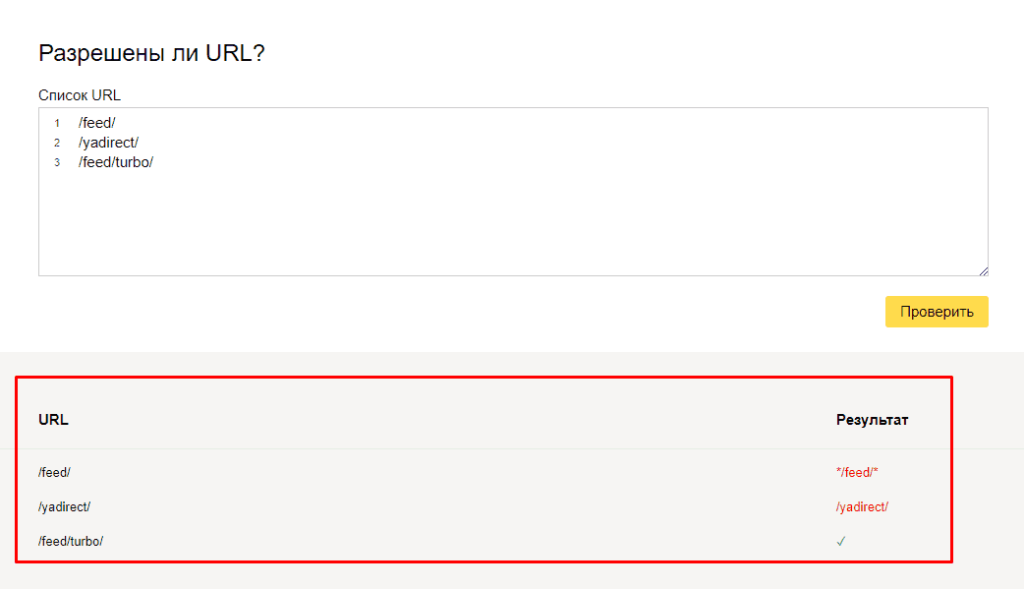
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
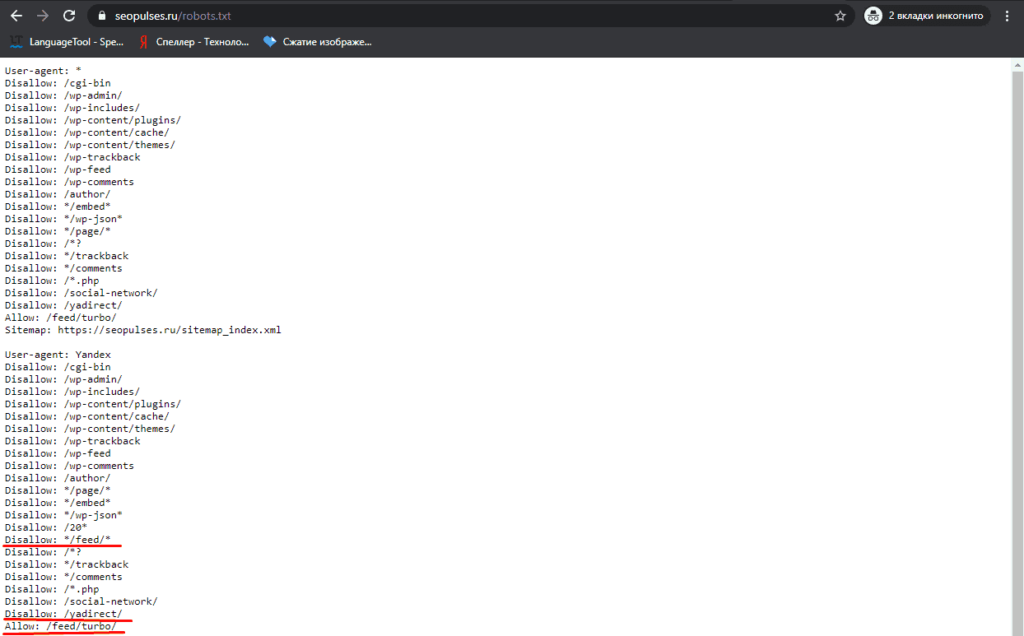
В нашем случае мы проверяем эти правила.


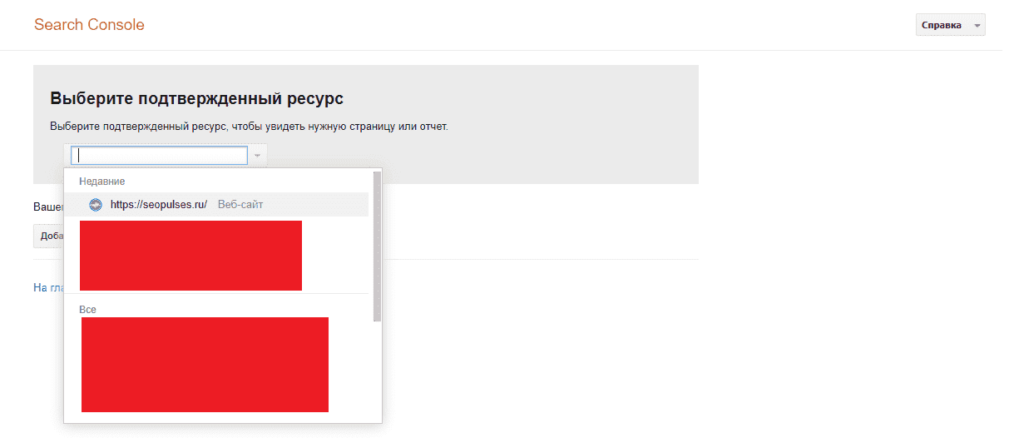
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.

Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
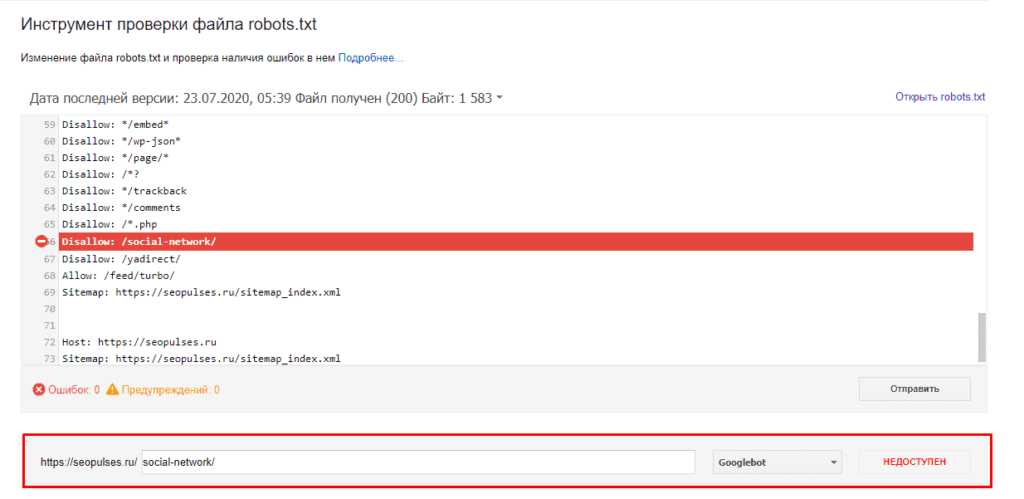
, то можно увидеть, что страница заблокирована в файле robots.txt.</p><p><span itemprop="image" itemscope itemtype="https://schema.org/ImageObject"><img itemprop="url image" decoding="async" src="https://24rek.ru/wp-content/uploads/2021/07/hl3til0x.png"></img><img width="1024" height="646" src=)
Подписывайтесь на наш канал в Яндекс.Дзен
Подписывайтесь на наши социальные сети