
В этом уроке вы изучите передовые методы веб-автоматизации Python: использование Selenium с ”безголовым» браузером, экспорт очищенных данных в CSV-файлы и обертывание кода очистки в класс Python.
Курс самоучитель python с нуля c задачами и объяснением возможен в конце статьи.
Один из уроков ниже.
Python автоматизация рутинных задач
Предположим, что вы когда либо уже некоторое время слушаете музыку на bandcamp, и вам хочется вспомнить песню, которую вы слышали несколько месяцев назад.
Конечно, вы можете покопаться в истории Вашего браузера и проверить каждую песню, но это может быть нудно… все, что вы помните, это то, что вы слышали песню несколько месяцев назад, и что она была в электронном жанре.
”Разве не было бы здорово, — думаете вы про себя, — если бы у меня была запись моей истории прослушивания? Я могу просто посмотреть электронные песни двухмесячной давности, и я обязательно найду их.”
Сегодня вы создадите базовый класс Python, который называется BandLeader подключением к bandcamp.com, транслирует музыку из раздела «discovery» на первой странице и отслеживает историю прослушивания.
История прослушивания будет сохранена на диске в CSV-файле. Затем вы можете изучить этот CSV-файл в своем любимом приложении для электронных таблиц или даже с помощью Python.
Если у вас был некоторый опыт работы с веб-скребком в Python, вы знакомы с выполнением HTTP-запросов и использованием Pythonic API для навигации по DOM. Сегодня вы будете делать то же самое, но с одним отличием.
Сегодня вы будете использовать полноценный браузер, работающий в безголовом режиме, чтобы делать HTTP-запросы за вас.
Безголовый браузер — это обычный веб-браузер, за исключением того, что он не содержит видимого элемента пользовательского интерфейса. Как и следовало ожидать, он может делать больше, чем просто делать запросы: он также может визуализировать HTML (хотя вы его не видите), хранить информацию о сеансе и даже выполнять асинхронную сетевую связь, запустив код JavaScript.
Если вы хотите автоматизировать современный веб, безголовые браузеры необходимы.
Установка в Python
Ваш первый шаг, прежде чем запустить Python автоматизация рутинных задач и писать одну строку Python, заключается в установке поддерживаемого Selenium WebDriver для вашего любимого веб-браузера. В дальнейшем вы будете работать с Firefox, но Chrome тоже может легко работать.
Предполагая, что путь ~/.local/bin находится в вашем исполнении PATH, вот как вы установили бы Firefox WebDriver, называемый geckodriver, на машине Linux:
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz $ tar xvfz geckodriver-v0.19.1-linux64.tar.gz $ mv geckodriver ~/.local/bin
Затем вы устанавливаете пакет selenium, используя pip или что вам нравится. Если вы создали виртуальную среду для этого проекта, вы просто набираете:
$ pip install selenium
Примечание: Если вы когда либо почувствуете себя потерянным во время этого урока — python практическое руководство, полную демонстрацию кода можно найти на GitHub .
Теперь пришло время для тест-драйва.
Тестовое вождение безголового браузера
Чтобы проверить, что все работает, вы решаете попробовать базовый веб-поиск через DuckDuckGo. Вы запускаете свой предпочтительный интерпретатор Python и вводите следующее:
>>>
>>> from selenium.webdriver import Firefox >>> from selenium.webdriver.firefox.options import Options >>> opts = Options() >>> opts.set_headless() >>> assert opts.headless # Operating in headless mode >>> browser = Firefox(options=opts) >>> browser.get('https://duckduckgo.com')
До сих пор вы создали безголовый браузер Firefox и перешли к https://duckduckgo.com нему . Вы создали Options экземпляр и использовали его для активации безголового режима, когда передавали его Firefox конструктору. Это сродни набору firefox -headless текста в командной строке.

КУРСЫ ОБУЧЕНИЯ ПРОГРАММИРОВАНИЮ
Курс python для начинающих dict import django opencv modules while
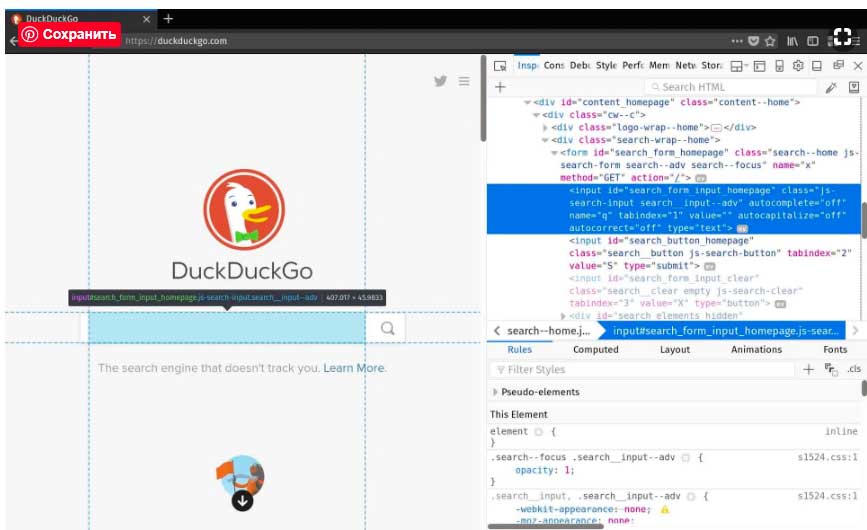
Теперь, когда страница загружена,вы можете запросить DOM с помощью методов, определенных для вашего новоиспеченного browser объекта. Но откуда вы знаете, о чем спрашивать?
Лучший способ-открыть веб-браузер и использовать его инструменты разработчика для проверки содержимого страницы. Прямо сейчас вы хотите получить доступ к поисковой форме, чтобы отправить запрос. Проверив домашнюю страницу DuckDuckGo, вы обнаружите, что элемент формы поиска <input>имеет id атрибут "search_form_input_homepage". Это как раз то, что тебе было нужно:
Переключите подсказки REPL и вывод данных
Вы нашли форму поиска, использовалиsend_keys метод для ее заполнения, а затем submit метод для выполнения поиска "Real Python". Вы можете проверить верхний результат:
Переключите подсказки REPL и вывод данных. Real Python — Real Python
Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up …
https://realpython.com
Во-первых, bandcamp разработал свой сайт для людей, чтобы получать удовольствие от использования, а не для скриптов Python для доступа программно. Когда вы звоните next_button.click(), реальный веб-браузер отвечает, выполняя некоторый код JavaScript.
Если вы попробуете его в своем браузере, то увидите, что проходит некоторое время, пока каталог песен прокручивается с плавным анимационным эффектом. Если вы попытаетесь повторно tracks заполнить переменную до завершения анимации, вы можете получить не все треки, а некоторые, которые вам не нужны.
Каково же решение? Вы можете просто поспать секунду, или, если вы просто запускаете все это в оболочке Python, вы, вероятно, даже не заметите. В конце концов, вам тоже нужно время, чтобы печатать.
Еще один небольшой изъян-это то, что можно обнаружить только путем экспериментов. Вы пытаетесь запустить тот же код снова:
Но вы заметили нечто странное. len(tracks)не равно 8 даже 8 при том, что должна отображаться только следующая партия. Копнув немного дальше, вы обнаружите, что ваш список содержит некоторые треки, которые были показаны ранее. Чтобы получить только те треки, которые действительно видны в браузере, вам нужно немного отфильтровать результаты.
Попробовав несколько вещей, вы решаете сохранить трек только в том случае, если его x координаты на странице попадают в ограничивающую рамку содержащего элемента. Контейнер каталога имеет class значение "discover-results". Вот как вы действуете:
>>>
>>> discover_section = self.browser.find_element_by_class_name('discover-results') >>> left_x = discover_section.location['x'] >>> right_x = left_x + discover_section.size['width'] >>> discover_items = browser.find_element_by_class_name('discover_items') >>> tracks = [t for t in discover_items if t.location['x'] >= left_x and t.location['x'] < right_x] >>> assert len(tracks) == 8
Построение класса в Python
Если вы устали перепечатывать одни и те же команды снова и снова в своей среде Python, вам следует сбросить некоторые из них в модуль. Все это есть в python практическое руководство. Базовый класс для вашей манипуляции bandcamp должен делать следующее:
- Инициализируйте безголовый браузер и перейдите к bandcamp
- Ведите список доступных треков
- Поддержка поиска большего количества треков
- Воспроизведение, пауза и пропуск треков
Вот основной код, все на одном дыхании:
from selenium.webdriver import Firefox from selenium.webdriver.firefox.options import Options from time import sleep, ctime from collections import namedtuple from threading import Thread from os.path import isfile import csv BANDCAMP_FRONTPAGE='https://bandcamp.com/' class BandLeader(): def __init__(self): # Create a headless browser opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Track list related state self._current_track_number = 1 self.track_list = [] self.tracks() def tracks(self): ''' Query the page to populate a list of available tracks. ''' # Sleep to give the browser time to render and finish any animations sleep(1) # Get the container for the visible track list discover_section = self.browser.find_element_by_class_name('discover-results') left_x = discover_section.location['x'] right_x = left_x + discover_section.size['width'] # Filter the items in the list to include only those we can click discover_items = self.browser.find_elements_by_class_name('discover-item') self.track_list = [t for t in discover_items if t.location['x'] >= left_x and t.location['x'] < right_x] # Print the available tracks to the screen for (i,track) in enumerate(self.track_list): print('[{}]'.format(i+1)) lines = track.text.split('\n') print('Album : {}'.format(lines[0])) print('Artist : {}'.format(lines[1])) if len(lines) > 2: print('Genre : {}'.format(lines[2])) def catalogue_pages(self): ''' Print the available pages in the catalogue that are presently accessible. ''' print('PAGES') for e in self.browser.find_elements_by_class_name('item-page'): print(e.text) print('') def more_tracks(self,page='next'): ''' Advances the catalogue and repopulates the track list. We can pass in a number to advance any of the available pages. ''' next_btn = [e for e in self.browser.find_elements_by_class_name('item-page') if e.text.lower().strip() == str(page)] if next_btn: next_btn[0].click() self.tracks() def play(self,track=None): ''' Play a track. If no track number is supplied, the presently selected track will play. ''' if track is None: self.browser.find_element_by_class_name('playbutton').click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number - 1].click() def play_next(self): ''' Plays the next available track ''' if self._current_track_number < len(self.track_list): self.play(self._current_track_number+1) else: self.more_tracks() self.play(1) def pause(self): ''' Pauses the playback ''' self.play()
Довольно аккуратно. Вы можете импортировать это в свою среду Python и запускать bandcamp программно! Но подождите, разве вы не начали все это, потому что хотели отслеживать информацию о вашей истории прослушивания?
Сбор структурированных данных
Ваша последняя задача состоит в том, чтобы отслеживать песни, которые вы на самом деле слушали. Как вы можете это сделать? Что вообще означает слушать что-то на самом деле? Если вы просматриваете каталог, останавливаясь на несколько секунд на каждой песне, считается ли каждая из этих песен? Скорее всего, нет. Вы собираетесь позволить некоторому «исследовательскому» времени учитывать ваш сбор данных.
Теперь ваши цели заключаются в том, чтобы:
- Сбор структурированной информации о текущей проигрываемой дорожке
- Ведите “базу данных » треков
- Сохраните и восстановите эту » базу данных” на диске и с диска
Вы решаете использовать namedtuple для хранения отслеживаемой информации. Именованные кортежи хороши для представления пакетов атрибутов без привязки к ним функциональности, немного напоминающей запись базы данных:
TrackRec = namedtuple('TrackRec', [ 'title', 'artist', 'artist_url', 'album', 'album_url', 'timestamp' # When you played it ])
Чтобы собрать эту информацию, вы добавляете метод в BandLeader класс. Возвращаясь к инструментам разработчика браузера, вы находите правильные HTML-элементы и атрибуты, чтобы выбрать всю необходимую вам информацию.
Кроме того, вы хотите получить информацию о текущей воспроизводимой дорожке только в том случае, если в данный момент там действительно играет музыка. К счастью, проигрыватель страниц добавляет "playing"класс к кнопке воспроизведения всякий раз, когда играет музыка, и удаляет его, когда музыка останавливается.
Имея в виду эти соображения, вы пишете несколько методов:
def is_playing(self): ''' Returns `True` if a track is presently playing ''' playbtn = self.browser.find_element_by_class_name('playbutton') return playbtn.get_attribute('class').find('playing') > -1 def currently_playing(self): ''' Returns the record for the currently playing track, or None if nothing is playing ''' try: if self.is_playing(): title = self.browser.find_element_by_class_name('title').text album_detail = self.browser.find_element_by_css_selector('.detail-album > a') album_title = album_detail.text album_url = album_detail.get_attribute('href').split('?')[0] artist_detail = self.browser.find_element_by_css_selector('.detail-artist > a') artist = artist_detail.text artist_url = artist_detail.get_attribute('href').split('?')[0] return TrackRec(title, artist, artist_url, album_title, album_url, ctime()) except Exception as e: print('there was an error: {}'.format(e)) return None
Для хорошей меры вы также изменяете play()метод, чтобы отслеживать текущую воспроизводимую дорожку:
def play(self, track=None): ''' Play a track. If no track number is supplied, the presently selected track will play. ''' if track is None: self.browser.find_element_by_class_name('playbutton').click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number - 1].click() sleep(0.5) if self.is_playing(): self._current_track_record = self.currently_playing()
Далее, вы должны вести какую-то базу данных. Это и не только есть в python практическое руководство. Хотя в долгосрочной перспективе он может плохо масштабироваться, вы можете далеко пойти с простым списком. Вы добавляете self.database = []к BandCamp__init__()своему методу. Поскольку вы хотите, чтобы прошло некоторое время до ввода TrackRec объекта в базу данных, вы решаете использовать инструменты потоковой обработки Python для запуска отдельного процесса, который поддерживает базу данных в фоновом режиме.
Вы предоставите _maintain()метод BandLeader экземплярам, которые будут выполняться в отдельном потоке. Новый метод будет периодически проверять значение self._current_track_record и добавлять его в базу данных, если оно новое.
Вы начнете поток, когда будет создан экземпляр класса, добавив в него некоторый код.__init__():
# The new init def __init__(self): # Create a headless browser opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Track list related state self._current_track_number = 1 self.track_list = [] self.tracks() # State for the database self.database = [] self._current_track_record = None # The database maintenance thread self.thread = Thread(target=self._maintain) self.thread.daemon = True # Kills the thread with the main process dies self.thread.start() self.tracks() def _maintain(self): while True: self._update_db() sleep(20) # Check every 20 seconds def _update_db(self): try: check = (self._current_track_record is not None and (len(self.database) == 0 or self.database[-1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) except Exception as e: print('error while updating the db: {}'.format(e)
Если вы никогда не работали с многопоточным программированием на Python, вам следует прочитать об этом! Для вашей настоящей цели вы можете думать о потоке как о цикле, который выполняется в фоновом режиме основного процесса Python (того, с которым вы взаимодействуете напрямую). Каждые двадцать секунд цикл проверяет несколько вещей, чтобы увидеть, нужно ли обновлять базу данных, и если да, добавляет новую запись. Довольно круто.
Самый последний шаг в Python автоматизация рутинных задач — это сохранение базы данных и восстановление из сохраненных состояний. Используя пакет csv, вы можете гарантировать, что ваша база данных находится в очень портативном формате и остается пригодной для использования, даже если вы откажетесь от своего замечательного BandLeader класса!
__init__()Метод должен быть еще раз изменен, на этот раз, чтобы принять путь к файлу, где вы хотите сохранить базу данных. Вы хотите загрузить эту базу данных, если она доступна, и периодически сохранять ее, когда она обновляется. Обновления выглядят следующим образом:
def __init__(self,csvpath=None): self.database_path=csvpath self.database = [] # Load database from disk if possible if isfile(self.database_path): with open(self.database_path, newline='') as dbfile: dbreader = csv.reader(dbfile) next(dbreader) # To ignore the header line self.database = [TrackRec._make(rec) for rec in dbreader] # .... The rest of the __init__ method is unchanged .... # A new save_db() method def save_db(self): with open(self.database_path,'w',newline='') as dbfile: dbwriter = csv.writer(dbfile) dbwriter.writerow(list(TrackRec._fields)) for entry in self.database: dbwriter.writerow(list(entry)) # Finally, add a call to save_db() to your database maintenance method def _update_db(self): try: check = (self._current_track_record is not None and self._current_track_record is not None and (len(self.database) == 0 or self.database[-1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) self.save_db() except Exception as e: print('error while updating the db: {}'.format(e)
Voilà! Вы можете слушать музыку и вести запись того, что вы слышите! Удивительно.
Что-то интересное в вышеприведенном заключается в том, что использование namedtuple действительно начинает окупаться. При преобразовании в формат CSV и из него вы используете преимущества упорядочения строк в файле CSV для заполнения строк в TrackRec объектах. Аналогично, вы можете создать строку заголовка CSV-файла, обратившись к этому TrackRec._fields атрибуту. Это одна из причин, по которой использование кортежа имеет смысл для столбчатых данных.

Флексбокс froggy курс flexbox флексы css flexbox уроки
Что дальше и чему вы научились?
Вы могли бы сделать гораздо больше! Вот несколько быстрых идей, которые могли бы использовать мягкую сверхдержаву Python + Selenium:
- Вы можете расширить
BandLeaderкласс, чтобы перейти на страницы альбома и воспроизвести найденные там треки. - Возможно, вы решите создать плейлисты на основе ваших любимых или наиболее часто слышимых треков.
- Возможно, вы хотите добавить функцию автозапуска.
- Может быть, вы хотите запрашивать песни по дате, названию или исполнителю и создавать плейлисты таким образом.
Но это ничтожная часть того, чему вы научитесь из курса.
Скачать курс Отчеты и автоматизация на Python PDF, HTML, email
О курсе ниже:
https://www.udemy.com/course/ittensive-python-pdf/
Вы узнали, что Python может делать все, что может делать веб-браузер, и немного больше. Вы можете Python автоматизация рутинных задач скачать и легко написать сценарии для управления экземплярами виртуальных браузеров, которые работают в облаке. Вы можете создавать ботов, которые взаимодействуют с реальными пользователями или бездумно заполняют формы! Идите вперед и автоматизируйте!