
Очистка и предварительная обработка данных для начинающих с кодом в Python
Обработка извлечение текстовой информации в Python, а так же очистка и подготовка данных является наиболее важным первым шагом в любом проекте искусственного интеллекта и машинного обучения. Это нормально, что большая часть времени — до 70% — тратится на очистку данных.
В данном посте я проведу вас через начальные шаги очистки и предварительной обработки данных в Python, начиная с импорта самых популярных библиотек до фактического кодирования функций.
Очистка представляет собой процесс обнаружения и исправления или удаления поврежденных либо неточных записей из набора записей, таблицы или базы данных и включает выявление неполных, неправильных, неточных либо неактуальных частей с целью последующей замены, изменения либо удаления грязных, возможно неточных данных.
Курс программы на питоне примеры для начинающих будет доступен в конце статьи.
Шаг 1. Загрузить набор данных в Python
Первое, что вам нужно сделать — импортировать библиотеки для предварительной обработки. Существует множество библиотек, но наиболее популярными и важными в целях работы с данными являются NumPy, Matplotlib и Pandas.
NumPy — это библиотека, используемая для математических вещей. Пандас — лучший инструмент импорта и управления наборами данных. Matplotlib — это библиотека создания графики.
Для реализации библиотек вы можете использовать псевдоним, это общий способ сделать сие. Нужно выполнить сей шаг, вам просто надо ввести следующее в свой код:
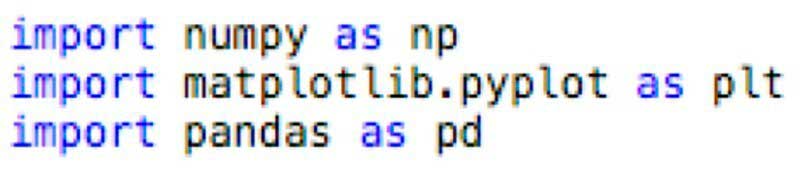
С помощью этого простого кода в вашей программе вы сейчас можете использовать библиотеки в вашем проекте.
В последствии того, как вы загрузили свой набор данных и назвали его файлом.csv, вам нужно будет загрузить его в DataFrame Pandas, чтобы изучить его и выполнить некоторые основные задачи очистки, удалив информацию, которая вам не нужна, что замедлит обработку.
Обычно эти задачи включают в себя:
Удалить первую строку, иногда содержит странный текст вместо заголовков столбцов. Текущий текст предотвращает правильный анализ набора данных библиотекой Пандас. Если нужно удалить эту информацию, вы можете реализовать следующий код:

Удалить столбцы с текстовыми объяснениями, которые нам не понадобятся, столбцы url и другие ненужные столбцы. Код выполнения выглядит следующим образом:
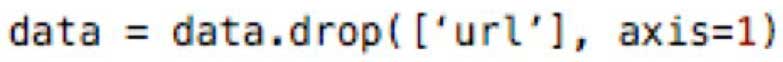
Где находится “url”, вы можете заключить столбец, который хотите удалить.
Удалить все столбцы с одним значением с более чем 50% отсутствующих значений, делаем дабы работать быстрее. Обратите внимание на это, если набор данных достаточно велик, чтобы он оставался значимым. Код, который вы должны реализовать, выглядит следующим образом:
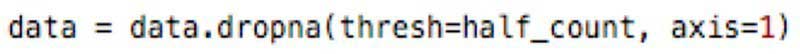
Также рекомендуется называть обработанный набор по-разному, дабы держать его отдельно от необработанных данных. Гарантирует, что у вас все еще есть исходные, если вам нужно вернуться к ним.
Шаг 2. Сканирование набора данных в Python
Теперь у вас есть данные, с которыми вы собираетесь работать, хотя было сделано несколько основных изменений, вы все равно должны потратить некоторое время на их изучение и понимание того, какую функцию представляет каждый столбец. Данный ручной обзор набора данных важен для предотвращения ошибок в анализе и процессе моделирования.
Чтобы упростить процесс, вы можете создать DataFrame с именами столбцов, типами данных, значениями первой строки и описанием словаря данных. Когда вы исследуете функции, вы можете обратить внимание на любой столбец, который:
- плохо отформатировано,
- требуется больше сведений, много предварительного обрабатывания, так как она должна стать полезной функцией
- содержит избыточную информацию,
поскольку данные вещи могут повредить анализ, если они обрабатываются неправильно.
Вы также должны обратить внимание на утечку информации, которая может привести к тому, что модель будет слишком подходящей. Связано с тем, что модель также будет учиться на функциях, которые будут доступны, когда мы будем использовать их для прогнозирования. Нам нужно убедиться, что наша модель обучена, используя только те данные, которые у нее были бы в то время, когда мы делаем прогноз.
С набором обработанных и изученных данных необходимо создать массив независимых переменных и вектор зависимых переменных. Во-первых, вы должны решить, какой столбец использовать в качестве целевого столбца в целях моделирования на основе вопроса, на который вы хотите ответить.
Например, если вы хотите предсказать развитие рака либо возможность одобрения кредита, вам нужно найти столбец со статусом заболевания независимо от того, предоставляется ли кредит или нет, это будут целевые столбцы в каждой проблеме.
Например, если целевой столбец является последним, вы можете создать массив независимых переменных, написав следующий код:
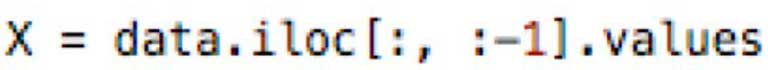
Первые две точки означают, что мы хотим взять любые строки из нашего набора dat, тогда как :-1 означает, что мы хотим взять все столбцы, кроме последнего. Метод .values в конце означает, что мы хотим каждое значения.
Чтобы иметь вектор зависимых переменных только с данными последнего столбца, вы можете написать:
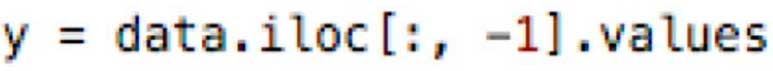
Шаг 3. Подготовка функций машинного обучения
Наконец, пришло время провести подготовительную работу по очистке функций алгоритмов машинного изучения. Дабы очистить набор данных, необходимо обрабатывать недостающие значения и категориальные характеристики, потому что математика, лежащая в основе большинства моделей машинного изучения, предполагает, что они являются числовыми и не содержат недостающих значений.
Кроме того, библиотека Scikit Learn возвращает ошибку, если вы пытаетесь обучить модель, такую как линейная регрессия и логистическая регрессия, используя данные, содержащие пропущенные или нечисловые значения.
Отсутствие их является, пожалуй, наиболее распространенной чертой нечистых данных. Значения обычно принимают форму NaN так же None.
Существует несколько причин отсутствия значений, иногда отсутствуют значения, потому что они не существуют, потому, что сбор инфы неадекватен, или потому, что ввод данных плохой.
Например, если кто-то несовершеннолетний, и вопрос относится к людям старше 18 лет, то вопрос будет иметь недостающее значение. В таких случаях было бы ошибкой заполнять значение для этого вопроса.
Существует несколько способов заполнения недостающих значений:
- Вы можете удалить строки, если набор данных достаточно велик, а процент пропущенных значений высок-более 50%, например.
- Вы можете заполнить каждые нулевые переменные 0, если числовое значение.
- Вы можете заполнить пропущенные значения средним или наиболее частым значением в столбце.
- Вы также можете заполнить недостающие значения любым значением, которое приходит непосредственно сразу в том же столбце.
Решения зависят от типа данных, того, что вы хотите сделать с ними, и причины отсутствия значений. На самом деле, просто потому, что что-то популярно, не обязательно означает, что это правильный выбор. Наиболее распространенной стратегией является использование среднего значения, но в зависимости от таковых, вы можете придумать совершенно другой подход.
Машинное изучение использует только числовые значения, тип с плавающей запятой, а так же целые числа. Однако наборы данных часто содержат объект как тип, поэтому становится необходимым преобразовать его в числовой.
В большинстве случаев категориальные значения дискретны и могут быть закодированы как фиктивные переменные, назначая число каждой категории. Самый простой способ-использовать One Hot Encoder, указав индекс столбца, над которым вы хотите работать. Код будет выглядеть следующим образом:

Определенным типом несоответствия данных является формат дат, dd / mm/YY и mm/dd / YY в одних и тех же столбцах. Ваши значения даты могут быть не в правильном типе, и не позволит вам эффективно выполнять манипуляции и получать из них информацию. На сей раз вы можете использовать пакет datetime для фиксации типа даты.
Масштабирование важно, если вам нужно указать, что изменение в одной величине не равно другому изменению в другой. С помощью масштабирования вы убедитесь, что, хотя некоторые функции велики, они не будут использоваться в качестве основного предиктора. Например, если в прогнозировании используется возраст и зарплата человека, некоторые алгоритмы будут уделять больше внимания зарплате, потому что она больше, что не имеет никакого смысла.
Нормализация включает в себя преобразование или преобразование набора данных в нормальное распределение. Некоторые алгоритмы, такие как машины поддержки векторов, сходятся намного быстрее в нормализованных данных, поэтому имеет смысл нормализовать их в целях достижения наилучших результатов.
Существует множество способов масштабирования функций. Проще говоря, мы помещаем все наши функции в один и тот же масштаб, важность — ни одна из них не доминировала над другой. Например, вы можете использовать класс StandardScaler из пакета sklearn.preprocessing для настройки и преобразования набора данных:
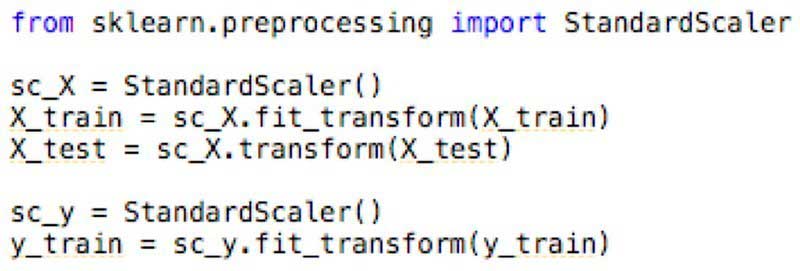
Вам не нужно использовать fit для тестовых данных, вам просто нужно применить преобразование.
Чтобы быть уверенным, что у вас еще есть необработанные данные, рекомендуется хранить окончательный вывод каждого раздела или этапа рабочего процесса в отдельном файле csv. Таким образом, Вы сможете вносить изменения в поток обрабатывания, без необходимости пересчитывать все.
Как и ранее, вы можете сохранить DataFrame как .csv с использованием функции Pandas to_csv (), как показано ниже:

Это лишь основные шаги, необходимые для работы с большим набором данных, очистки и подготовки данных любых проектов машинного изучения. Существуют и другие способы очистки, которые вы можете найти полезными.
Но с этим я хочу, понимания, что важно правильно организовать и отсортировать перед разработкой любой модели. Лучшие и чистые данные превосходят лучшие алгоритмы. Если вы используете очень простой алгоритм вместе с чистыми, результаты впечатляют.
Помните, что если вам еще трудно всё объяснено здесь, у меня есть в вашем распоряжении шаблон, разработанный на Python, который вы можете использовать в плане очистки и предварительной обработки, и, таким образом, вы можете начать с ваших проектов.
Мы заканчиваем объяснение. Готова основа для очистки и предварительной обработки данных в Python, поэтому я оставляю вам следующий вопрос, какие из следующих утверждений, по вашему мнению, верны?
Вариант 1: Очистка и предварительная обработка выполняется сразу, как модель машинного изучения построена.
Неправильный Ответ. Очистка и предварительная обработка данных — это первый шаг в любом проекте машинного изучения.
Вариант 2: алгоритмы машинного изучения принимают любой тип, от числа до типа объекта.
Неправильный Ответ. Алгоритмы машинного изучения принимают только числовые, целочисленные и плавающие данные.
Вариант 3: в случае потери данных эту информацию можно заполнить средним значением.