Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на Opencart
- User-agent: *
- Disallow: /*route=account/
- Disallow: /*route=affiliate/
- Disallow: /*route=checkout/
- Disallow: /*route=product/search
- Disallow: /index.php?route=product/product*&manufacturer_id=
- Disallow: /admin
- Disallow: /catalog
- Disallow: /system
- Disallow: /*?sort=
- Disallow: /*&sort=
- Disallow: /*?order=
- Disallow: /*&order=
- Disallow: /*?limit=
- Disallow: /*&limit=
- Disallow: /*?filter=
- Disallow: /*&filter=
- Disallow: /*?filter_name=
- Disallow: /*&filter_name=
- Disallow: /*?filter_sub_category=
- Disallow: /*&filter_sub_category=
- Disallow: /*?filter_description=
- Disallow: /*&filter_description=
- Disallow: /*?tracking=
- Disallow: /*&tracking=
- Disallow: *page=*
- Disallow: *search=*
- Disallow: /cart/
- Disallow: /forgot-password/
- Disallow: /login/
- Disallow: /compare-products/
- Disallow: /add-return/
- Disallow: /vouchers/
- Host: https://24rek.ru
- Sitemap: https://24rek.ru/sitemap_index.xml

 https://serpstat.com/robots.txthttps://netpeak.net/robots.txt
https://serpstat.com/robots.txthttps://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):


Если его нет, то достаточно создать новый файл.
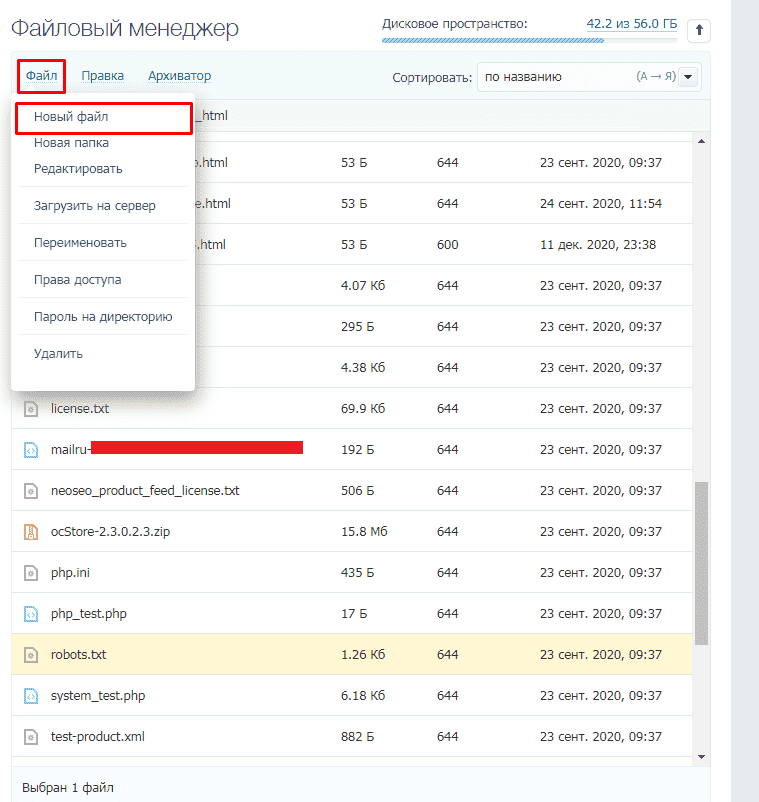

Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
. Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.</p><h4>Пример #1</h4><p># Полностью закрывает весь сайт от индексации</p><p>User-agent: *</p><p>Disallow: /</p><h4>Пример #2</h4><p># Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/</p><p>Disallow: /category1/</p><h4>Пример #3</h4><p># Блокирует для скачивания страницу раздела /category2/</p><p>User-agent: *</p><p>Disallow: /category1/$</p><h4>Пример #4</h4><p># Дает возможность сканировать весь сайт просто оставив поле пустым</p><p>User-agent: *</p><p>Disallow:</p><p><strong>Важно! </strong>Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.</p><h3>Allow</h3><p>Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.</p><h4>Пример #1</h4><p># Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.</p><p>Disallow: */feed/*</p><p>Allow: /feed/turbo/</p><h4>Пример #2</h4><p># разрешает скачивание файла doc.xml</p><p># разрешает скачивание файла doc.xml</p><p>Allow: /doc.xml</p><h3>Sitemap</h3><p>Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.</p><p><p>Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:</p><ul><li>Следует указывать полный URL, когда относительный адрес использовать запрещено;</li><li>На нее не распространяются остальные правила в файле robots.txt;</li><li>XML-карта сайта должна иметь в URL-адресе домен сайта.</li></ul><h4>Пример</h4><p># Указывает карту сайта</p><p>Sitemap: https://serpstat.com/sitemap.xml</p><h3>Clean-param</h3><p>Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.</p><h4>Пример #1</h4><p>#для адресов вида:</p><p>www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243</p><p>www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243</p><p>#robots.txt будет содержать:</p><p>User-agent: Yandex</p><p>Disallow:</p><p>Clean-param: s /forum/showthread.php</p><h4>Пример #2</h4><p>#для адресов вида:</p><p>www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df</p><p>www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae</p><p>#robots.txt будет содержать:</p><p>User-agent: Yandex</p><p>Disallow:</p><p>Clean-param: sid /index.php</p><p>Подробнее о данной директиве можно прочитать здесь:</p><p>https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/</p><h3>Crawl-delay</h3><p><p><strong>Важно! </strong>Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.</p><p>Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.</p><h4>Пример</h4><p># Допускает скачивание страницы лишь раз в 3 секунды</p><p>Crawl-delay: 3</p><h2>Как проверить работу файла robots.txt</h2><h3>В Яндекс.Вебмастер</h3><p>В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.</p><p><span itemprop="image" itemscope itemtype="https://schema.org/ImageObject"><img itemprop="url image" decoding="async" src="https://24rek.ru/wp-content/uploads/2021/07/joj1c0x2.png"></img><img width="1196" height="884" src=)
Также можно скачать другие версии файла или просто ознакомиться с ними.


Как видим из примера все работает нормально.


Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.


Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.


Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
